
A.X-4.0-VL-Light
January 2024 ~ May 2025
My Contributions
Vision-Language Model Development
- Defined the model’s direction and strengths by focusing on token efficiency and enhanced understanding of Korean culture and Korean-language documents.
- Developed the training pipeline, reviewing frameworks such as Megatron-LM, NeMo, and DeepSpeed.
- Designed and validated training strategies based on PLM and instruction-tuned models.
- Selected the VLM architecture to highlight the strengths of the A.X-4.0-VL model.
- Coordinated external collaborations for academic evaluations, Korean document understanding, and the development of a proprietary VLM benchmark for domestic certifications.
- Built a comprehensive evaluation pipeline integrating the proprietary benchmark, AI Hub datasets, and lmms-eval for VLM performance assessment.
What is A.X-4.0-VL-Light?
A.X 4.0 VL Light (pronounced “A dot X”) is a vision-language model (VLM) optimized for Korean vision and language understanding as well as enterprise deployment. Built upon A.X 4.0 Light, A.X 4.0 VL Light has been further trained on diverse multimodal datasets, with a particular focus on large-scale multimodal Korean datasets, to deliver exceptional performance in domestic business applications.
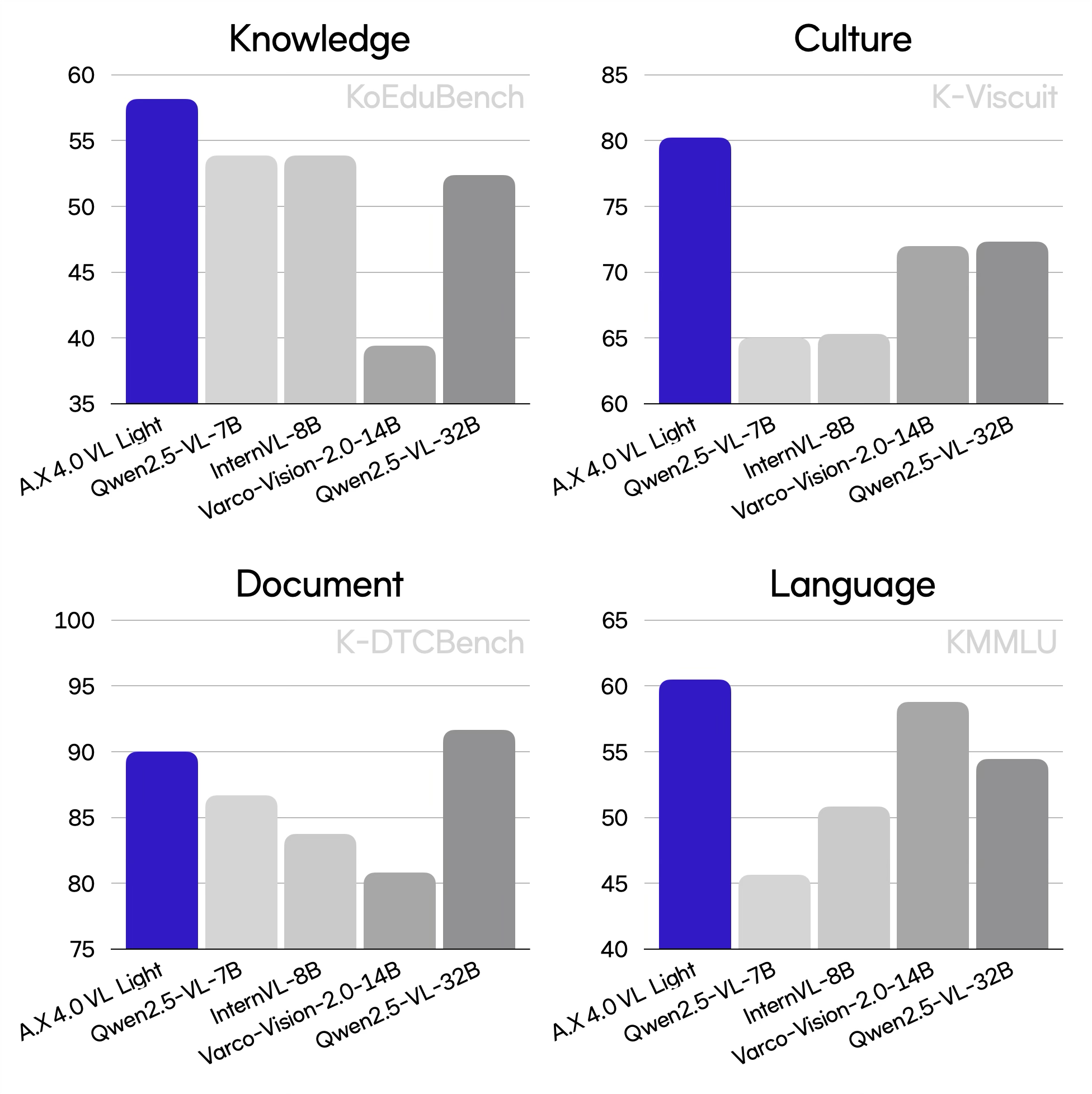
- Superior Korean Proficiency in Vision and Language: Achieved an average score of 79.4 on Korean image benchmarks, outperforming Qwen2.5-VL-32B (73.4), despite having a significantly smaller model size. On Korean text benchmarks, recorded an average score of 60.2, comparable to VARCO-VISION-2.0-14B (60.4), while using only half the model size.
- Deep Cultural Understanding: Scored 80.2 on K-Viscuit, a multimodal benchmark designed to evaluate cultural and contextual comprehension in Korean, exceeding Qwen2.5-VL-32B (72.3).
- Advanced Document Understanding: Attained a score of 89.8 on KoBizDoc, a benchmark focused on understanding complex document structures, including charts and tables, performing comparably to Qwen2.5-VL-32B (88.8).
- Efficient Token Usage: A.X 4.0 VL Light utilizes approximately 41% fewer text tokens compared to Qwen2.5-VL for the same Korean input, enabling significantly more cost-effective and efficient processing.